
#Глава 5 Расследование с базами данных: проверка качества данных

Джаннина Сеньини является приглашенным профессором в Школе Журналистики Колумбийского университета города Нью-Йорк. До февраля 2014 года Сегнини возглавляла команду журналистов и программистов в La Nacion, в Коста Рике. Ее команда публиковала расследования, основанные на сборе, анализе и визуализации баз данных. С начала 2000 года Сегнини занималась обучением сотен журналистов на территории Латинской Америки, США, Европы и Азии в области расследований и журналистики данных. Сегнини была трижды награждена Национальной Премией по Журналистике имени Jorge Vargas Gene, Национальной Премией по Журналистике имени Pio Víquez, Почетной Премией по Журналистике имени Gabriel García Márquez, призом the Ortega y Gasset от ежедневной газеты El País, в Испании, премией за Лучшее Журналистское Расследование по делам о коррупции от Transparency International для Латинской Америки и Карибских островов (TILAC), а также премией имени Maria Moors Cabot от Колумбийского Университета. Сегнини также была участником и обладателем премии Nieman Fellow (2001-2002) при Гарвардском университете
Никогда прежде у журналистов не было столько доступа к информации. Более трех эксабайтов данных — эквивалент 750 миллионов DVD-дисков — создаются каждый день, и это число каждые 40 месяцев удваивается. Глобальное производство данных измеряется нынче иоттабайтами (один иоттабайт равен 250 триллионам DVD с данными). Уже ведутся обсуждения насчет новых измерений, необходимых после того как мы перешагнем порог измерения иоттабайтами.
Рост объемов и скорости производства данных может ошеломляюще действовать на многих журналистов, многие из которых не привыкли использовать для исследований и изложения такие большие объемы.
Но срочность и готовность использовать данные и технологии для их обработки не должны отвлекать нас от базового стремления к точности. Чтобы в полной мере понять значение данных, мы должны уметь видеть различие между сомнительной и качественной информацией, а также уметь разыскивать среди всего этого шума реальные истории.
Важный урок, который я усвоила за два десятилетия использования данных для расследований, состоит в том, что данные лгут. Лгут так же, как люди, а то и больше, ведь данные часто создаются и поддерживаются людьми.
Данные предназначены для представления реальности в конкретный момент времени. Как же мы можем проверить, соответствует ли набор данных реальности?
Есть две ключевые задачи по проверке информации в расследованиях, где данные играют основную роль: первичная оценка должна проводиться сразу же после получения данных, а выводы из данных проверяются в конце расследования или на этапе анализа.
A. Первичная проверка информации
Правило первое — опросить всех и вся. Когда дело доходит до использования данных, такого понятия, как полностью надежный источник, не существует.
Например, поверите ли вы базе данных, опубликованных Всемирным банком? Большинство журналистов, которым я задавала этот вопрос, сказали: «Да». Журналисты считают Всемирный банк надежным источником. Давайте проверим это предположение с помощью двух наборов данных Всемирного банка, чтобы продемонстрировать, как проверять данные, а также укрепиться во мнении, что даже так называемые «надежные источники» могут предоставлять ошибочную информацию. Я буду следовать процедуре, указанной в приведенном ниже графике.
1.Обладаем ли мы полным набором данных?
В начале занятий я рекомендую изучить крайние значения (высокие или низкие) для каждой переменной в наборе данных, а затем посчитать, сколько записей (строк) есть в пределах каждого из возможных значений.
Например, Всемирный банк публикует базу данных с более чем 10 000 независимых оценок по более чем 8600 проектам, разработанным этой организацией по всему миру начиная с 1964 года.
Всего лишь за счет сортировки в порядке возрастания по столбцу «Затраты на кредитование» мы можем быстро убедиться, что во многих строках в колонке «Стоимость» значится ноль.
Если создать сводную таблицу для подсчета, сколько проектов имеют нулевую стоимость, можно увидеть, что больше половины из них (53 процента) имеют нулевую стоимость.
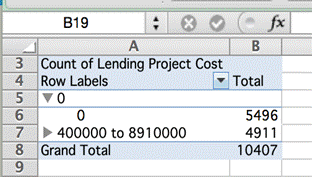
Это означает, что любой, кто проводит анализ по стране, региону или году с учетом стоимости проектов, окажется неправ, если он не принял в расчет всех записей без установленной стоимости. Набор данных в том виде, в каком он представлен, приведет к неточным выводам.
Банк публикуетдругую базу данных, которая предположительно содержит индивидуальные данные по каждому проекту, профинансированному (а не только оцененному) этой организацией начиная с 1947 года.
Буквально открыв api.csv файл в Excel (версия по состоянию на 7 декабря 2014 года), можно убедиться, что данные загрязнены и содержат много переменных, объединенных в одной ячейке (например, названия секторов и стран). Но еще более примечательным является тот факт, что этот файл не содержит всех проектов, профинансированных с 1947 года.
Базы данных фактически включают в себя только 6352 из более чем 15 000 проектов, профинансированных Всемирным банком, начиная с 1947 года (банк, в конце концов, исправил эту ошибку. К 12 февраля 2015 года тот же файл включал уже 16 215 записей).
После всего лишь небольшого промежутка времени, потраченного на изучение данных, мы видим, что Всемирный банк не включает в свои базы данных стоимость всех своих проектов, публикует грязные данные и не удосуживается учитывать все свои проекты как минимум в одной версии данных. С учетом всего этого, какого качества данных ждать от менее надежных учреждений?
Другой пример несоответствия базы данных я нашла во время семинара, который проводила в Пуэрто-Рико. Мы использовали базу данных государственных контрактов Патентного ведомства. 72 контракта за прошлый год имели в графе стоимости отрицательные значения (-10 000 000 долларов).
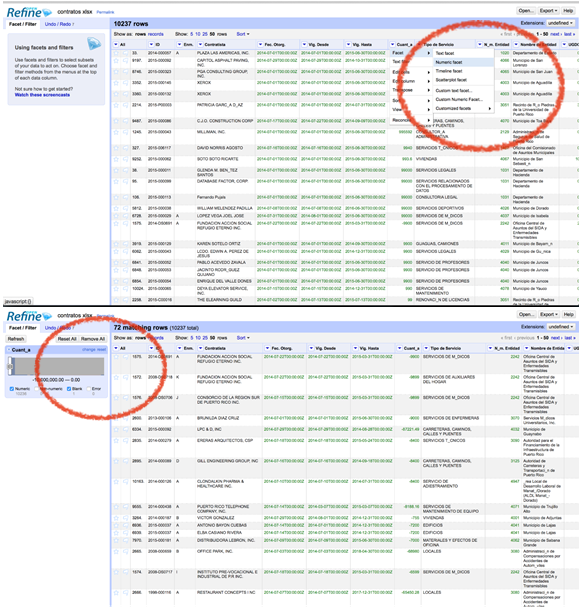
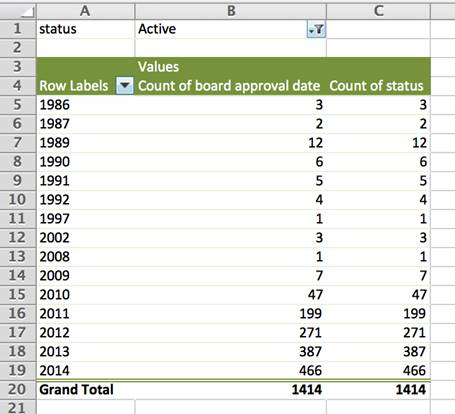
Отличным средством для быстрого просмотра и оценки качества баз данных является Open Refine. На первой иллюстрации вы видите, как создается «числовой» фильтр для работы с полем Cuantía (сумма). Этот фильтр группирует ячейки с определенным диапазоном значений. Это позволяет вам выбрать любой диапазон, который охватывает нужную последовательность подборок данных.
&34
Вторая иллюстрация показывает, как вы можете сформировать гистограмму с диапазоном значений, включенных в базу данных. Записи могут быть отфильтрованы по значениям путем перемещения стрелок внутри графика. То же самое может быть сделано в отношении дат и текстовых значений.
- Присутствуют ли дубликаты записей?
Одной из распространенных ошибок, которые совершают при работе с данными, является невыявление повторяющихся записей.
При обработке неструктурированных данных или информации о людях, компаниях, событиях либо операциях первым шагом является поиск уникального идентификатора для каждого элемента.
В случае с базой данных проектов Всемирного банка каждый проект идентифицируется с помощью уникального «ID проекта». Базы данных других структур могут включать уникальный идентификационный номер или, в случае государственных контрактов, номер контракта.
Если посчитать, сколько записей есть в базе по каждому проекту, мы видим, что некоторые из них повторяются до трех раз. Поэтому любой расчет на основе каждой страны, региона или даты без устранения дубликатов приведет к ошибочным выводам.
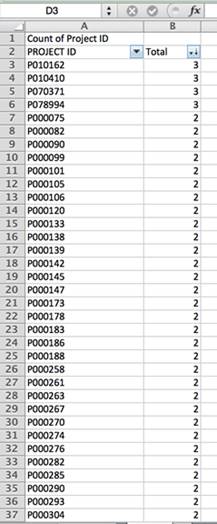
Записи дублируются, потому что несколько типов оценки были выполнены для каждой из них. Чтобы исключить повторы, мы должны выбрать, какая из всех оценок является наиболее надежной. В этом примере наиболее достоверными кажутся записи, известные как «Отчеты об аттестации [PAR]», поскольку они представляют наиболее вескую картину проведенной оценки. Они разработаны Independent Evaluation Group, которая самостоятельно и случайным образом анализирует 25 процентов проектов Всемирного банка в год. Группа отправляет своих экспертов «в поле», чтобы оценить результаты этих проектов и провести независимый анализ.
- Точны ли представленные данные?
Один из лучших способов оценить достоверность набора данных — это выбрать образцовую запись и сравнить ее с реальностью.
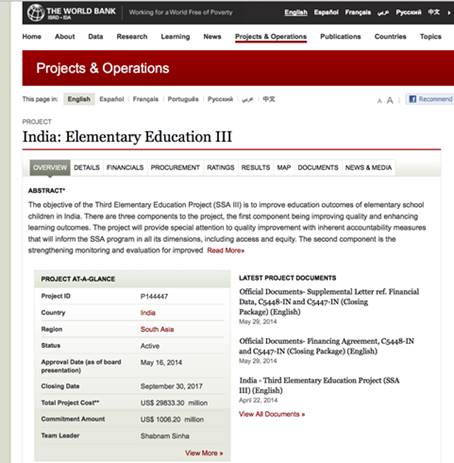
Если отсортировать базу данных Всемирного банка, которая якобы содержит все проекты, разработанные этим учреждением, в порядке убывания стоимости, то мы найдем проект в Индии, который был самым дорогостоящим. В списке он фигурирует с общей суммой 29 833 300 000 долларов.
Если поискать уникальный номер проекта (P144447) в Google, то можно получить доступ к проектной документации, где фигурирует стоимость кредита в 29 833 млн долларов. Это означает, что цифра является точной.
Данное упражнение по проверке данных через значимый образец записей рекомендуется повторять систематически.
- Оценка целостности данных
С момента ввода в компьютер до момента нашей работы с этой информацией данные проходят через несколько процессов ввода, хранения, передачи и регистрации. На любом этапе они могут подвергаться манипуляции со стороны людей и информационных систем.
Нередко бывает так, что при этом связи между таблицами или полями теряются либо путаются, а некоторые переменные по той или иной причине не обновляются. Поэтому крайне важно проводить тесты на целостность.
Например, не так уж и редко можно найти проекты, указанные в базе данных Всемирного банка как «активные» через много лет после даты их утверждения, даже если налицо вероятность, что многие из них уже утратили этот статус.
Для проверки я создала сводную таблицу и сгруппировала проекты по году их утверждения. Затем я отфильтровала данные, чтобы показать только те, которые в столбце «статус» отмечены как «активные». Мы видим, что 17 проектов, утвержденных в 1986, 1987 и 1989 годах, все еще числятся в базе данных активными. Почти все из них находятся в Африке.
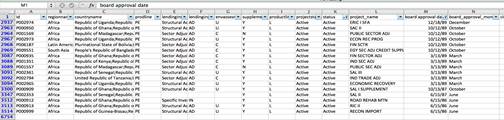
В данном случае необходимо прояснить непосредственно у специалистов Всемирного банка, остаются ли эти проекты активными спустя почти 30 лет.
Для оценки соответствия данных Всемирного банка мы могли бы, конечно, провести и другие тесты. Например, было бы неплохо рассмотреть, все ли получатели кредитов («заемщики») соответствуют организациям и/или фактическим правительствам стран, перечисленным в графе «Название страны», а также правильно ли указаны регионы, в которых расположены эти страны (графа «Название региона»).
- Расшифровка кодов и сокращений
Один из самых верных способов отпугнуть журналиста — это показать сложную информацию, запутанную специальными кодами и терминологией. Этот трюк любят чиновники и непрозрачные организации. Они рассчитывают, что мы не понимаем смысла того, что они нам рассказывают.
Но те же самые коды и аббревиатуры можно использовать для сокращения количества символов в ячейках и нормализации объемов хранящихся данных. Почти каждая система баз данных, неважно, государственная или частная, использует коды или аббревиатуры для классификации информации.
В сущности, почти все люди, структуры и вещи в этом мире имеют один или несколько приписанных к ним кодов. Люди имеют идентификационные номера документов, номера социального страхования, коды клиентов банка, номера налогоплательщика, номера карт часто летающих пассажиров, номера студенческих билетов, удостоверений сотрудников и пр.
Например, металлические стулья в мире международной торговли проходят под кодом 940179. Каждый корабль в мире имеет уникальный номер IMO. Многие вещи имеют один свойственный только им номер: объекты недвижимости, транспортные средства, самолеты, компании, компьютеры, смартфоны, пушки, танки, таблетки, разводы, браки...
Необходимо учиться расшифровывать коды и понимать, как они используются, чтобы быть в состоянии видеть логику за базами данных и, что еще более важно, их отношения, связи друг с другом.
Каждый из 17 миллионов грузовых контейнеров в мире имеет уникальный идентификатор, и мы можем отследить их, если понимаем, что первые четыре буквы идентификатора связаны с их владельцем. Владельца вы можете запросить в этой базе данных. Так эти четыре буквы таинственного кода становятся средством для получения большей информации.
База данных оцененных проектов Всемирного банка полна кодов и сокращений, но, на удивление, это учреждение не публикует ни единого глоссария, описывающего смысл всех этих аббревиатур. Некоторые акронимы являются даже устаревшими и приводятся лишь в старых документах.
Колонка «Инструмент кредитования», к примеру, классифицирует все проекты в зависимости от 16 типов кредитных инструментов, используемых Всемирным банком: APL, DPL, DRL, ERL, FIL, LIL, NA, PRC, PSL, RIL, SAD, SAL, SIL, SIM, SSL и TAL. Чтобы осмыслить эти данные, необходимо исследовать значение данных аббревиатур. В противном случае вы не будете знать, что, скажем, ERL соответствует экстренным кредитам странам, которые недавно прошли через вооруженный конфликт или стихийное бедствие.
Коды SAD, SAL, SSL и PSL относятся к спорной программе Структурной перестройки Всемирного банка, применявшейся в течение 80-х и 90-х годов. Она предоставляла займы странам в пору экономического кризиса в обмен на внесение этими странами изменений в свою экономическую политику с целью сокращения бюджетных дефицитов. Программа была поставлена под сомнение из-за неоднозначного влияния на развитие общества, имевшего место в ряде стран.
По данным Банка, с конца 90-х она стала больше сориентирована на кредиты для «развития», чем на кредиты на «реструктуризацию». Однако согласно базе данных, между 2001 и 2006 годами более 150 кредитов были отмечены кодом «Структурная перестройка».
Так это ошибки в базе данных, или же программа Структурной перестройки была продлена на следующий век?
Данный пример показывает, как расшифровка аббревиатур служит не только более адекватной практике оценки качества данных, но и, что более важно, пригождается для поиска сюжетов, представляющих общественный интерес.
B. Проверка данных после проведенного анализа
Заключительный этап верификации должен быть направлен на ваши выводы и проведенный анализ. Это, пожалуй, наиболее важный этап проверки — своего рода лакмусовая бумажка для осознания, является ли ваша история или первоначальная гипотеза правомерной.
В 2012 году я работала редактором в составе одной междисциплинарной команды в Ла Насьон (Коста-Рика). Мы решили исследовать одну из наиболее важных государственных субсидий от правительства, известную как Avancemos. Эта субсидия предусматривала выплаты ежемесячных стипендий малоимущим учащимся государственных школ, чтобы они не бросали учебу.
После получения базы данных по всем учащимся-бенефициарам мы добавили туда имена их родителей. Затем мы запросили другие базы данных, касающиеся недвижимости, транспортных средств, зарплат и компаний в стране. Это позволило нам создать исчерпывающий перечень активов тех семей (эти данные в Коста-Рике открытые и становятся доступны через Верховный суд по избирательным делам).
Наша гипотеза состояла в том, что кое-кто из тех 167 000 учащихся-бенефициаров жил не так уж и бедно, а потому не должен был получать ежемесячных выплат.
Прежде чем приступить к анализу, мы позаботились о том, чтобы оценить и очистить все записи, а также проверить отношения между каждым человеком и его активами.
Анализ вскрыл, что среди прочего отцы примерно 75 учащихся имели ежемесячный доход свыше 2000 долларов США (минимальный уровень заработной платы для неквалифицированного рабочего в Коста-Рике составляет 500 долларов) и что более 10 тысяч из них имели в собственности дорогую недвижимость или транспортные средства.
Но лишь когда мы пошли с посещениями по их домам, мы смогли выяснить то, чего нам не могли бы показать никакие данные сами по себе: эти дети действительно жили в нищете со своими матерями, потому что их бросили отцы.
Об их отцах до назначения пособия никто никогда не спрашивал. В результате государство на протяжении многих лет финансировало из государственных средств образование многих детей, брошенных армией безответственных отцов.
Эта история обобщает лучший урок, который я вынесла за годы моих расследований данных: даже самый лучший анализ данных не может заменить журналистику и полевой контроль на местах.
