

Bölüm 5: Veritabanlarını araştırmak: Verinin kalitesini doğrulamak
 Giannina Segnini Colombia Üniversitesi Gazetecilik Bölümü'nde misafir profesör olarak dersler veriyor. Segnini, Şubat 2014'e kadar Kosta Rika'da La Nacion'da gazeteciler ve mühendislerden oluşan bir ekibin başındaydı. Ekip herkese açık veritabanlarını toplayıp analiz edip görselleştirerek soruşturmacı gazetecilik hikayelerini çıkarmaya odaklıydı. 2000'den bu yana, Segnini, soruşturmacı gazetecilik, Bilgisayar Destekli Habercilik (Computer Assisted Reporting) ve veri gazeteciliği alanlarında Latin Amerika'da, Amerika Birleşik Devletleri'nde, Avrupa'da ve Asya'da yüzlerce gazeteciyi eğitti.
Giannina Segnini Colombia Üniversitesi Gazetecilik Bölümü'nde misafir profesör olarak dersler veriyor. Segnini, Şubat 2014'e kadar Kosta Rika'da La Nacion'da gazeteciler ve mühendislerden oluşan bir ekibin başındaydı. Ekip herkese açık veritabanlarını toplayıp analiz edip görselleştirerek soruşturmacı gazetecilik hikayelerini çıkarmaya odaklıydı. 2000'den bu yana, Segnini, soruşturmacı gazetecilik, Bilgisayar Destekli Habercilik (Computer Assisted Reporting) ve veri gazeteciliği alanlarında Latin Amerika'da, Amerika Birleşik Devletleri'nde, Avrupa'da ve Asya'da yüzlerce gazeteciyi eğitti.
Segnini Jorge Vargas Gene Ulusal Gazetecilik ödülüne üç kez layık görüldü. Pio Viqu Ulusal Gazetecilik Ödülü, Gabriel García Márquez Gazetecilikte Mükemmeliyet Ödülü, El País Ortega y Gasset Ödülü, Latin Amerika ve Karayipler Uluslararası Şeffaflık Derneği Yolsuzluk Konusunda En İyi Gazetecilik Araştırması Ödülü ve Colombia Üniversitesi Maria Moors Cabot ödülü sahibi. Segnini ayrıca daha önce (2001-2002) Harvard Üniversitesi Nieman Fellow'uydu.
Gazetecilerin bilgiye bu kadar çok erişim sahibi olduğu başka bir dönem yaşanmadı. Her gün üç exabyte'tan daha fazla veri - 750 milyon DVD'ye eşit - üretiliyor ve bu sayı her 40 ayda ikiye katlanıyor. Küresel veri üretimi bugün yottabyte'lar ile ölçülüyor. (Bir yottabyte 250 trilyon DVD verisiyle eşdeğer.) Yottabyte'ı aştığımızda kullanmamız gereken ölçüm ile ilgili tartışmalar şimdiden başladı.
Veri üretiminin hızı ve hacmindeki yükseliş araştırma ve hikaye anlatıcılığı için büyük miktarlardaki veriyle çalışmamış birçok gazeteci için baş edilemez olabilir. Ancak veriyi ve onu işleyecek teknolojiyi kullanma konusundaki acele ve heves, dikkatimizi, yerine getirmek zorunda olduğumuz doğru olma görevinden ayırmamıza sebep olmamalı. Verinin değerini tamamiyle yakalayabilmek için, şüpheli ve kaliteli bilgi arasındaki farkı ayırt edebilmeli ve gürültünün içerisindeki gerçek hikayeleri keşfedebilmeliyiz.
Araştırmalar için veriyle çalışırken geçtiğimiz 20 yılda öğrendiğim önemli derslerden biri, verinin en az insanlar kadar, hatta daha feci şekilde yalan söyleyebileceği oldu. Sonuçta, veri, sıklıkla insanlar tarafından üretilen ve sürdürülebilen bir şey.
Veri, zamanın belli bir anına dair gerçekliği sunan şey anlamına geliyor. Peki, bir veri seti gerçekliğe tekabül ediyorsa onu nasıl doğrulayabiliriz?
Veri merkezli araştırmada iki kilit doğrulama görevi yerine getirilmeli: Veri elde edildikten hemen sonra bir iç değerlendirme gerçekleştirilmeli; ve sonuçlar araştırmanın sonunda veya analiz aşamasında doğrulanmalı.
A. İlk doğrulama
İlk kural her şeyi ve herkesi sorgulamaktır. Mevzu veriyi kullanmaya gelince, titiz gazetecilikten daha güvenilir bir kaynak yoktur.
Örneğin, Dünya Bankası tarafından yayınlanan bir veritabanına tamamen inanır mıydınız? Bu soruyu sorduğum birçok gazeteci, inanacağını söylüyor; Dünya Bankası'nı güvenilir bir kaynak olarak değerlendiriyor. Şimdi bu varsayımı Dünya Bankası'na ait iki veri setiyle test ederek verinin nasıl doğrulanacağını gösterelim ve güvenilir addedilen kaynakların bile veride hata yapabileceği bilgisini pekiştirelim. Aşağıdaki grafikte özetlenmiş akışı izleyeceğim.
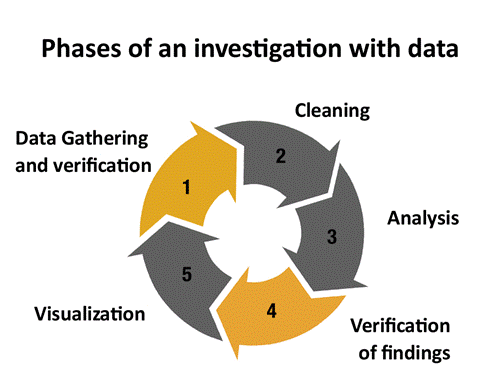
Görsel: veriyle araştırma aşamaları. 1) Veri toplama ve doğrulama 2) Temizleme 3) Analiz 4) Bulguların doğrulanması 5) Görselleştirme
- Veri tamamlanmış mı?
Önerdiğim ilk uygulama, bir veri setindeki her değişken için en uç değerleri (en yüksek ve en düşük) tespit etmek ve her olası değerde ne kadar kayıt (satır) listelendiğini saymak.
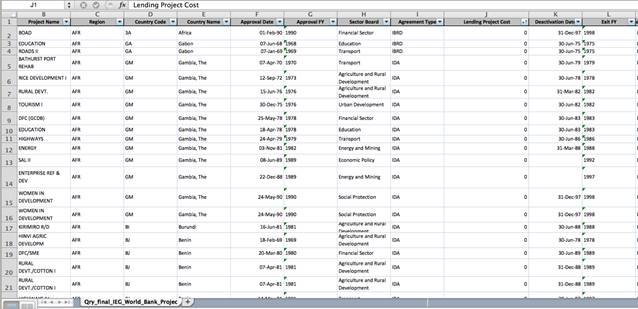
Örneğin, Dünya Bankası, 1964'ten bu yana dünya çapında gerçekleştirdiği 8 bin 600 proje üzerine yapılan 10 binden fazla bağımsız ölçümü içeren bir veri seti yayınladı.
Tabloda sadece Borç Alma Maliyeti (Lending Cost) sütununu artışa göre sıralayarak, masraf sütununda sıfır değerini içeren ve tekrar eden kayıtları hızlıca görebiliyoruz.
Eğer kaç tane projenin toplam kayıtlarla ilişkili sıfır maliyet içerdiğini görmek için bir pivot tablosu yaratırsak, yarısından fazlasının (yüzde 53) sıfır maliyet içerdiğini görebiliriz.
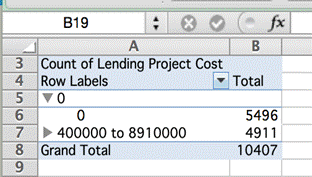
Bu, belirtilmeyen maliyet verilerinin, ülke, bölge veya yıl bazında projelerin maliyetlerini hesaplayan ya da analiz eden birinin yaptığı hesaplamayı yanıltacağı anlamına geliyor. Sağlanan veri seti doğru olmayan bir sonuca sebep olacak.
Dünya Bankası 1947'den bu yana fonlanan (ölçümlenen değil) her projenin tekil verisini içerdiğini belirttiği bir başka veri seti yayınladı.
Yalnızca Excel'deki (7 Aralık 2014 versiyonu) api.csv dosyasını açarak, verinin kirli olduğunu ve bir hücre içerisinde (sektör isimleri veya ülke isimleri gibi) birden fazla değişkenin bir arada olduğunu söylemek mümkün. Fakat dikkate değer bir diğer gerçek ise bu dosya 1947'den bu yana fonlanan tüm projeleri içermiyor.
Veritabanı Dünya Bankası'nın 1947'den bu yana fonladığı 15 binden fazla projeden yalnızca 6 bin 352'sini içeriyor. (Not: Banka nihayetinde bu hatayı düzeltti. 12 Şubat 2015 itibariyle, aynı dosya 16 bin 215 kayda sahip.)
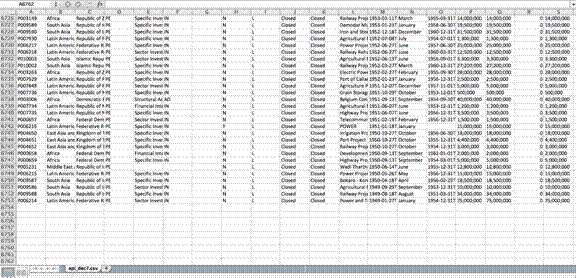
Veriyi incelemekle geçirdiğimiz belli bir sürenin ardından gördük ki Dünya Bankası veri tabanlarında yer alan projelerin hiçbirinin masraflarına yer vermiyor. Tamamen temizlenmemiş veri yayınlıyor ve veriyi en az bir versiyonda tüm projeleri kapsayacak şekilde yayınlamakta başarısızlığa uğruyor. Tüm bunlara bakıldığında, daha az güvenilir kurumların yayınladığı verinin kalitesinden ne beklerdiniz?
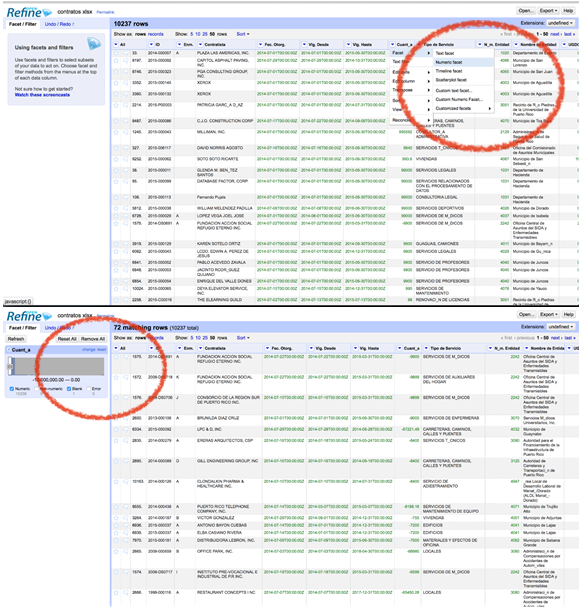
Porto Riko'da verdiğim bir atölye sırasında Maliye'nin herkese açık sözleşme veritabanını incelerken bir başka tutarsız veritabanı örneğiyle karşılaştım. Geçen yıla ait kamuya açık 72 sözleşmenin masraf kısımlarındaki değer (–10 milyon dolar) negatif.
Open Refine veri tabanlarının kalitesini hızlıca keşfetmek ve değerlendirmek için müthiş bir araç. Aşağıdaki ilk görselde, Open Refine'in Cuantía (Meblağ) kısmında sayısal "filtreleme" için nasıl kullanıldığını görüyorsunuz. Böylece sayılar, sayısal kutu sıraları olarak gruplanıyor. Bu da size ardışık sayı kutularını kapsayan herhangi bir sırayı seçme imkanı sağlıyor.
Aşağdaki ikinci görsel ise veritabanının içindeki değer seviyelerinden bir histogram yaratabildiğinizi gösteriyor. Grafiğin içindeki okları kaydırarak kayıtlar değerlere göre filtrelenebilir. Aynısı tarih ve metin değerleri için de yapılabilir.
- Tekrar eden kayıtlar var mı?
Veriyle çalışırken en sık karşılaşılan hatalardan biri de tekrar eden kayıtların varlığını farkedememektir.
Kişiler, şirketler, etkinlikler ya da kayıtlar ile ilgili veri ya da bilgiyi parçalara ayırırken yapılması gereken ilk adım her madde için bir eşsiz kimlik değişkeni aramaktır. Dünya Bankası'nın projelerin ölçümlerinin yer aldığı veritabanı örneğinde, her proje eşsiz bir kod ile ya da "Project ID" ile kimliklendirilmiş. Başka kuruluşların veritabanlarında da eşsiz bir kimlik numarası ya da, kamuya açık sözleşmeler örneğinde olduğu gibi, sözleşme numarası bulunabilir.
Veritabanındaki her proje için kaç kayıt olduğunu sayarsak, bazılarının üç defaya kadar tekrar ettiğini görürüz. Bu yüzden, tekrarları elemeden yapılan ülke, bölge ya da tarih bazlı veriye dayalı her hesaplama yanlış olacaktır.
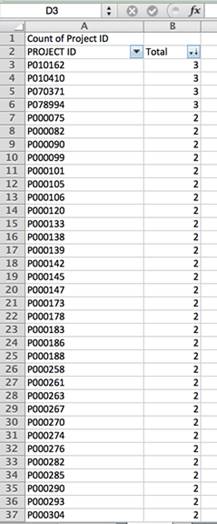
Bu örnekte, kayıtlar tekrar ediyor çünkü her biri için birden fazla ölçüm tipi kullanılmış. Tekrarları elemek için tüm ölçümlerden en güvenilir olanları seçmeliyiz. (Bu örnekte, Performans Ölçme Raporları [PARs] ölçüme dair daha güçlü bir perspektif çizdiği için en güvenilir kayıt olarak gözüküyor. Bunlar her yıl Dünya Bankası'nın projelerinin dörtte birini rastgele seçerek ölçen Bağımsız Ölçüm Grubu (IEG) tarafından geliştirildi. IEG, uzmanlarını sahaya gönderiyor ve bu projelerin sonuçlarını ölçerek bağımsız sonuç raporları hazırlıyor.)
- Veri hatasız mı?
Bir veri setinin güvenilirliğini tespit etmenin en iyi yöntemlerinden biri, örnek bir kaydı ele alarak onu gerçeklikle karşılaştırmaktır.
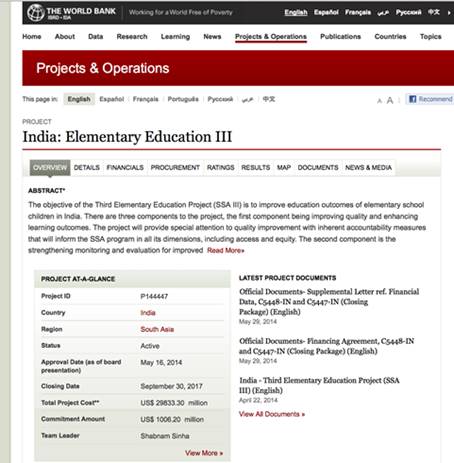
Eğer Dünya Bankası'nın -kurumun geliştirdiği tüm projeleri içerdiği iddia edilen- veritabanını masrafa göre azalan şekilde sıralarsak, en masraflı projenin, toplam 29,833,300,000 dolarlık masrafı ile Hindistan'daki bir proje olduğunu görebiliriz.
Eğer projenin numarasını (P144447) Google'da aratırsak, projenin 29 milyon dolara mal olduğunu gösteren orijinal kabul belgesine ulaşabiliriz. Bu, rakamın doğru olduğunu gösteriyor.
Kayıt örnekleri üzerinde bu doğrulama pratiğini sürekli tekrar etmek çok önemli.
- Verinin bütünlüğünü belirlemek
Bilgisayara ilk girildiği andan, bizim ona ulaştığımız ana kadar geçen sürede veri birçok girdi, depolama, çoğaltma ve kayıt aşamasından geçer. Herhangi bir aşamada insan eliyle veya bilgi sistemleri tarafından manipüle edilebilir.
Bu yüzden bazı tablo ve alanlar arasındaki ilişkinin kaybolduğu veya karıştığı, veya bazı değişkenlerin güncellenmediği sıklıkla görülür. Bütünlük testlerini uygulamak bu açıdan vazgeçilmezdir.
Örneğin, onaylanma tarihinden yıllar sonra bile, çoğu aktif olmasa da Dünya Bankası'nın veritabanında "aktif" olarak listelenmiş projeleri görmek şaşırtıcı olmaz.
Kontrol etmek için bir pivot tablo yarattım ve projeleri onaylanma tarihlerine göre grupladım. Sonra "durum" (status) sütununda "aktif" olarak işaretlenenleri gösterecek şekilde filtreledim. Şimdi, 1986, 1987 ve 1989'da kabul edilen 17 projenin veritabanında "aktif" olarak listelendiğini görebiliriz. Bunların neredeyse hepsi Afrika'da.
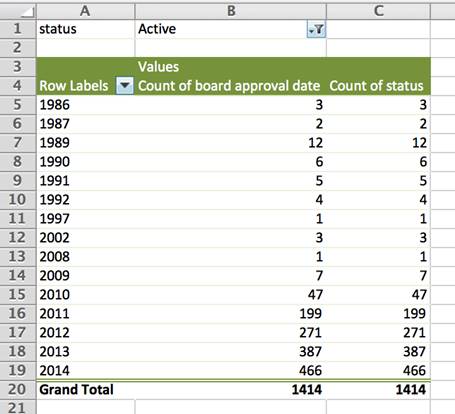
Bu örnekte, neredeyse 30 yılın ardından bu projelerin gerçekten hala aktif olup olmadığını doğrudan Dünya Bankası ile netleştirmek elzem.
Tabii ki Dünya Bankası'nın verisinin tutarlığını ölçmek için farklı testler de uygulayabiliriz.
- Kodlar ve akronimleri çözmek
Bir gazeteciyi korkutup kaçırmanın en iyi yöntemi ona özel bir terminoloji ve özel kodlarla hazırlanmış karmaşık bir bilgiyi göstermek. Bu azıcık şeffaflıkla yetinmek isteyen bürokratlar ve organizasyonlar tarafından tercih edilen bir kurnazlıktır. Bize verdikleri şeyin ne olduğunu anlayamamamızı bekliyorlar. Fakat kodlar ve akronimler ayrıca, karakter sayısını düşürmek, saklama kapasitesini iyi yönetmek için de kullanılabilir. Herkese açık veya özel, neredeyse her veritabanı sistemi bilgiyi sınıflandırmak için kod ve akronim kullanır.
Aslında bu dünya üzerindeki birçok insan, birçok kurum ve birçok şey bir veya birden fazla kodla ilişkilidir. Kişilerin kimlik numaraları, sosyal güvenlik numaraları, banka müşteri numaraları, vergi mükellefi numaraları, uçuş numaraları, öğrenci numaraları, çalışan numaraları gibi kodları bulunur.
Metal bir sandalye örneğin uluslararası ticaret dünyasında 940179 numaralı kod ile sınıflandırılmıştır. Dünya üzerindeki her geminin kendine özgü bir IMO numarası bulunur. Birçok şey kendine has tek bir numaraya sahiptir: mülkler, araçlar, uçaklar, şirketler, bilgisayarlar, akıllı telefonlar, silahlar, tanklar, haplar, boşanmalar, evlilikler...
Bu yüzden kodları nasıl çözeceğimizi öğrenmek, veritabanın arkasında yatan mantığı ve daha önemlisi veritabanındaki ilişkileri anlamamız için elzemdir.
Dünya üzerindeki 17 milyon kargo konteynırının her birinin kendine özgü bir numarası vardır ve eğer numaranın ilk dört hanesinin konteynırın sahibini gösterdiğini anlayabilirsek onları takip de edebiliriz. Sahipliği bu veritabanında sıralayabilirsiniz. Gizemli bir kodun ilk dört hanesi şimdi anlamlı bir bilgiye dönüşmüş oldu.
Dünya Bankası'nın ölçümlenen projeler veritabanı kodlar ve akronimlerle dolu ve şaşırtıcı bir şekilde, kurum bu kodların ne anlama geldiğini açıklayacak herhangi bir kılavuz yayınlamamış. Üstelik bu kodların bazıları artık kullanılmıyor, bazıları ise eski dökümanlarda kullanılıyor.
Örneğin, "Borç Belgesi" (Lending Instrument) sütunu, Dünya Bankası'nın projeleri fonlamak için kullandığı 16 farklı belgeye referans veriyor: APL, DPL, DRL, ERL, FIL, LIL, NA, PRC, PSL, RIL, SAD, SAL, SIL, SIM, SSL ve TAL. Veriden bir şey anlayabilmek için, bu akronimlerin ne anlama geldiğini araştırmak kaçınılmaz. Aksi takdirde ERL kısaltmasının yalnızca silahlı çatışma veya doğal afet yaşayan ülkelere verilen acil kredi (emergency loans) olduğunu anlayamazsınız.
SAD, SAL, SSL ve PSL kodları Dünya Bankası'nın 80'ler ve 90'larda uyguladığı Yapısal Uyum Programı'nı ifade ediyor. Program ekonomik kriz içerisinde olan ve ekonomi politikalarını toparlamak isteyen ülkelere cari açıklarını düşürebilmek için krediler sağlıyordu. (Program birçok ülkede yarattığı sosyal etki nedeniyle sorgulandı.)
Dünya Bankası'nın aktardığına göre 90'ların sonundan itibaren uyum amaçlı krediler yerine "kalkınma" amaçlı kredilere odaklanıldı. Fakat, veritabanının aktardığına göre 2001-2006 yılları arasında 150'den fazla kayıt Yapısal Uyum kodu altında onaylanmış.
Bunlar veritabanı hataları mı yoksa Yapısal Uyum Programı içinde bulunduğumuz yüzyıla da sarktı mı?
Bu örnek akronimleri deşifre etmenin yalnızca verinin kalitesini ölçmek için en iyi yöntem olması açısından değil, toplumun çıkarına hizmet edecek hikayeleri ortaya çıkarması açısından da önemli olduğunu gösteriyor.
B. Analizin ardından veriyi doğrulamak
Son doğrulama adımı bulgularınıza ve analizinize odaklanıyor. Bu acıklı test, ilk hipotezinizi ve hikayenizi doğrulayacağı için en önemli doğrulama adımı.
2012'de Kosta Rika'da La Nación'da disiplinler arası bir ekip için editör olarak çalışıyordum. "Avancemos" olarak bilinen en önemli devlet sübvansiyonlarından birini soruşturmaya karar verdik. Destek, okulu terketmenin önüne geçmek için durumu olmayan öğrencilere verilen aylık ücretleri kapsayan bir devlet yardımıydı.
Tüm yararlanıcı öğrencileri içeren veritabanını edindikten sonra, ailelerinin isimlerini ekledik. Ve diğer veritabanlarını ülkedeki mülklere, araçlara, maaşlara ve şirketlere göre sıraladık. Bu bize ailelerin mal varlıklarını gösteren kapsamlı bir liste sağladı. (Veri Kosta Rika'da Yüksek Mahkeme tarafından herkese açık hale getirilmişti.)
Hipotezimiz 167 bin yararlanıcı öğrencinin hepsinin kötü koşullarda yaşamadığı ve hepsinin bu aylık ücreti almaması gerektiğiydi.
Analiz etmeden önce tüm kayıtların temizlendiğinden, ölçüldüğünden ve her bir kişi ile mal varlığı arasındaki ilişkinin doğru olduğundan emin olduk.
Diğer bulgularla birlikte analiz gösterdi ki yaklaşık 75 öğrencinin babasının aylık 2 bin dolardan (Kosta Rika'da bir işçinin minimum maaşı 500 dolardır) fazla maaşı var. Ve 10 binden fazlası lüks araç ve mülke sahip.
Verinin tek başına bize asla söylemeyeceği şeyi, evlerine gidip görmeden kanıtlamamız imkansızdı: Bu çocuklar gerçekten anneleriyle birlikte yoksulluk içinde yaşıyorlardı çünkü babaları tarafından terkedilmişlerdi.
Kimse onlara yardımdan yararlanmadan önce babalarını sormamıştı. Sonuç olarak, devlet yardımlarla sorumsuz babalar ordusu tarafından terkedilmiş birçok çocuğun eğitimini finanse etmişti.
Bu hikaye, veriyle çalıştığım yıllar boyunca öğrendiğim en iyi ders oldu: En iyi veri analizi bile sahadaki gazeteciliğin ve sahada yapılan doğrulamanın yerini dolduramaz.
