
Глава 5: Истражување со помош на бази на податоци: Верификација на квалитетот на податоците
 Џанина Сењини (Giannina Segnini) во моментов работи како вонреден професор на Школата за новинарство на Универзитетот Колумбија во Њујорк. До февруари 2014 година, Сењини предводеше еден тим од новинари и инженери во весникот „Ла Насион“ (La Nacion), во Костарика.
Нејзиниот тим беше целосно посветен на изработка на истражувачки приказни преку собирање, анализа и визуелизација на јавни бази на податоци. Од 2000 година до денес, Сењини обучила стотици новинари од Латинска Америка, САД, Европа и Азија, во областите на истражувачкото новинарство, новинарството помогнато од компјутер и дата-новинарството.
Џанина Сењини (Giannina Segnini) во моментов работи како вонреден професор на Школата за новинарство на Универзитетот Колумбија во Њујорк. До февруари 2014 година, Сењини предводеше еден тим од новинари и инженери во весникот „Ла Насион“ (La Nacion), во Костарика.
Нејзиниот тим беше целосно посветен на изработка на истражувачки приказни преку собирање, анализа и визуелизација на јавни бази на податоци. Од 2000 година до денес, Сењини обучила стотици новинари од Латинска Америка, САД, Европа и Азија, во областите на истражувачкото новинарство, новинарството помогнато од компјутер и дата-новинарството.
Сењини трипати ја добила Националната новинарска награда „Хорхе Варгасе Гене“, а ги има добиено и Националната награда за новинарство „Пио Викез“, наградата за извонредно новинарство „Габриел Гарсија Маркез“, наградата „Ортега и Гасет“ на шпанскиот дневен весник „Ел Паис“, наградата за најдобро новинарско истражување на корупциски случај на „Транспаренси интернешнл“ за Латинска Америка и за Карибите, како и наградата „Марија Мурс Кебот“ што ја доделува Универзитетот „Колумбија“. Сењини е поранешен учесник на програмата Ниман (Nieman Fellow) на Универзитетот „Харвард“ во 2001 и во 2002 година.
Новинарите никогаш досега немале толку голем пристап до информации. Повеќе од три ексабајти податоци – што е еднакво на 750 милиони ДВД дискови – се создаваат секој ден, а нивниот број се дуплира на секои 40 месеци. Глобалната продукција на податоци денес се мери во јотабајти. (Еден јотабајт е еднаков на 250 трилиони ДВД дискови со податоци.) Веќе наголемо се разговара за новите мерки што ќе бидат потребни кога ќе ги надминеме јотабајтите.
За многумина новинари порастот на квантитетот и брзината на производството на податоци можат да се покажат како преголем залак за справување, и многумина новинари не се навикнати на користење огромен број податоци во истражувањето и во раскажувањето. Сепак, желбата и стремежот да се искористат податоците и достапните технологии за нивна обработка не треба да нè оттргнат од потрагата по точност во известувањето. За целосно да ја разбереме вредноста на податоците, мора да можеме да правиме разлика помеѓу сомнителните и квалитетните информации и да можеме во целиот тој шум да ги пронајдеме вистинските приказни.
Една значајна лекција што ја научив во текот на двете децении, колку што се служам со податоци во истражувањата, е дека податоците лажат исто толку колку што лажат и луѓето, а можеби и повеќе. Конечно, податоците често се создадени и одржувани од луѓе.
Податоците би требало да ја претставуваат реалноста во даден момент од времето. Како да верификуваме дека еден сет податоци соодветствува со реалноста?
Во текот на истражувања засновани врз податоци, треба да се извршат две клучни задачи за верификација: мора да се направи првична процена веднаш по добивањето на податоците; и, на крајот на фазата на истражување или анализа, треба да се верификуваат сите наоди.
A. Првична верификација
Првото и основно правило е да се сомневате во сè и во секого. Во користењето податоци за производство на внимателно новинарство без недостатоци, не постојат целосно веродостојни извори.
На пример, дали целосно би ѝ верувале на база на податоци објавена од Светската банка? Повеќето од новинарите на кои им го поставив тоа прашање велат дека би ѝ верувале; за нив, Светската банка е веродостоен извор. Да ја провериме таа претпоставка на два сетови податоци на Светската банка за да покажеме како се верификуваат податоците и да повториме дека дури и таканаречените веродостојни извори можат да достават погрешни податоци. Притоа, ќе го следам процесот прикажан во следниот графикон.
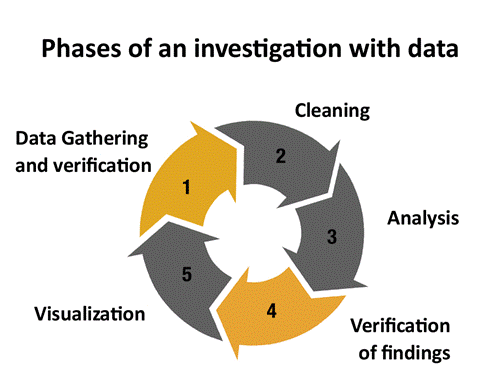
- Дали податоците се целосни?
Првата постапка што ја препорачувам е да се прегледаат екстремните (највисоките и најниските) вредности за секоја од варијабилите содржани во сетот податоци, и потоа да се изброи колку записи (редови) се наведени во секоја од можните вредности.
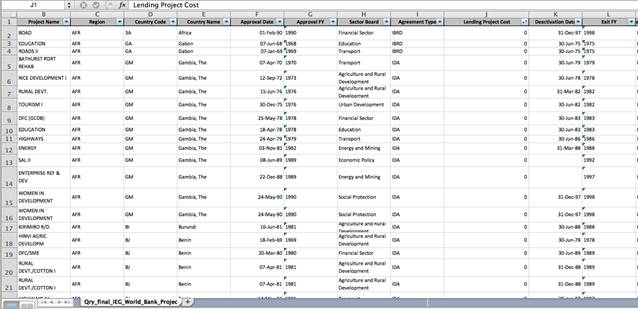
На пример, Светската банка објавува база на податоци со повеќе од 10.000 независни процени на повеќе од 8.600 проекти развивани од страна на организацијата во целиот свет, од 1964 година досега.
Доволно ќе биде да ја подредиме колоната „Трошоци на зајмувањето“ на табелата од најниската до највисоката вредност, и веднаш ќе утврдиме дека голем број записи имаат внес „нула“ во колоната за трошоците.
Ако креираме пивот-табела за да преброиме колку од проектите имаат нула трошоци, споредено со вкупниот број записи, ќе видиме дека повеќе од половината од нив (53 отсто) имале нула трошоци.
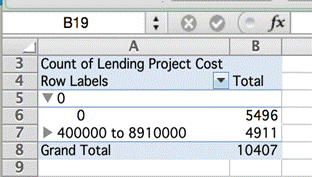
Тоа значи дека секој што изведува пресметка или анализа што ги вклучува трошоците на проектите по индивидуални држави, региони или години, ќе направи грешка ако не ги земе предвид сите внесови за кои нема наведено трошоци. Сетот податоци, таков како што е добиен, ќе води кон неточен заклучок.
Банката објавува една друга база на податоци што би требало да ги содржи индивидуалните податоци за секој проект финансиран (а не само оценуван) од организацијата од 1947 година досега.
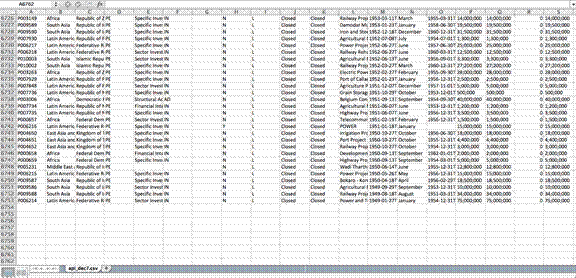
Доволно е да го отвориме api.csv документот во „Excel“ (верзијата на документот од 7 декември 2014 година), за да стане јасно дека податоците се нечисти и дека содржат многу варијабили комбинирани во една ќелија (на пример, имињата на секторите или имињата на државите). Уште поважно да се забележи е фактот дека документот не ги содржи сите проекти финансирани од 1947 година досега.
Всушност, базата на податоци содржи само 6.352 од повеќе од 15.000 проекти финансирани од Светската банка од 1947 година досега. (Забелешка: Светската банка подоцна ја поправи таа грешка. Истиот документ, прегледан на 12 февруари 2015 година, вклучуваше 16.215 записи.)
Еден сосема краток преглед на податоците покажа дека Светската банка не ги вклучува трошоците на сите проекти во своите бази на податоци, дека објавува нечисти податоци и дека не ги вклучила сите свои проекти во најмалку една верзија од податоците. Со оглед на погоре кажаното, какви ќе бидат вашите очекувања за квалитетот на податоците објавени од навидум помалку веродостојни институции?
Друг скорашен пример за неконзистентна база на податоци открив за време на работилницата што ја водев во Порторико, во која ја користевме базата на јавни договори на Државниот завод за ревизија. Од сите договори минатата година, 72 имаа негативна вредност ($-10.000.000) во полињата за внес на трошоците.
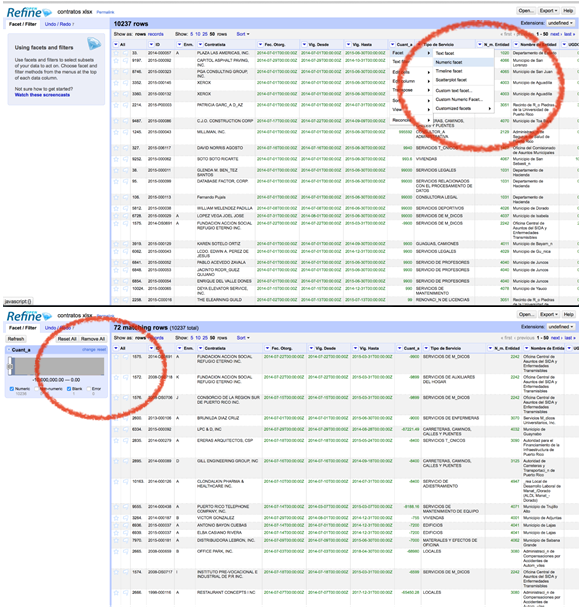
Open Refine е одлична алатка за брзо прегледување и процена на квалитетот на базите на податоци. На првата слика подолу можете да видите како „Open Refine“ може да се искористи за вршење нумерички „Facet“ (рамнење) во полето „Cuantia“ (Количество). Нумеричкото рамнење ги групира броевите во кошнички со нумерички опсег. Тоа ви овозможува да изберете опсег што се протега преку неколку последователни кошнички.
На втората слика е покажано дека можете да генерирате хистограм со опсегот на вредности вклучени во базата на податоци. Записите потоа можат да се филтрираат по вредност со поместување на стрелките во графиконот. Истото може да се направи со вредностите за датуми и за текст.
- Дали има дуплирани записи?
Една од грешките што често настануваат при работата со податоци е неидентификувањето на постоењето дуплирани записи.
Кога обработуваме дезагрегирани податоци или информации за луѓе, компании, настани или трансакции, првиот чекор секогаш треба да биде пребарување за уникатните идентификациски варијабили за секој од внесовите. Во случајот на базата на податоци за евалуација на проектите на Светската банка, секој проект се идентификува преку единствен код, односно „Project ID“. Базите на податоци на други субјекти можат да вклучуваат единствен идентификациски број или, во случајот на јавните договори, број на договор.
Ако преброиме колку записи има во базата на податоци за секој проект, ќе видиме дека некои од нив се повторуваат и до трипати. Оттаму, секоја пресметка по држава, регион или податок со користење на податоците, без елиминација на дупликатите, би била погрешна.
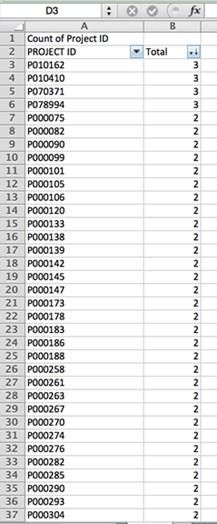
Во овој случај, записите се дуплицирани затоа што за секој од нив се извршени повеќе видови евалуација. За да ги елиминираме дупликатите, треба да избереме кои од направените процени се најверодостојни. (Во нашиот случај, записите под името Извештаи за оцена на перформансите [Performance Assessment Reports ‒ PAR] изгледаат најверодостојни затоа што нудат многу поцврста слика за евалуацијата. Извештаите ги развива Независната група за евалуација, која независно и по случаен избор прегледува 25 отсто од сите проекти на Светската банка за дадената година. Групата ги праќа своите експерти да извршат теренска процена на резултатите на проектите и да подготват независни евалуации.)
- Дали податоците се точни?
Еден од најдобрите начини за процена на веродостојноста на еден сет податоци е да се избере еден примерок од записите и тој да се спореди со реалната ситуација.
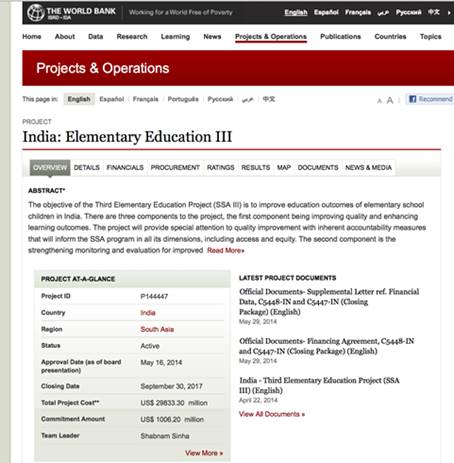
Ако базата на податоци на Светската банка – која наводно ги содржи сите проекти развиени од институцијата – ја подредиме од проект со најголеми кон проект со најмали трошоци, ќе видиме дека најскап бил еден проект во Индија. Вкупниот наведен износ на проектот е 29.833.300.000 американски долари.
Ако го пребараме бројот на проектот (P144447) на „Гугл“, можеме да ѝ пристапиме на оригиналната документација за одобрување и за проектот и за поврзаниот кредит, која наведува трошок од 29.833 милиони американски долари. Тоа значи дека бројката е точна.
Се препорачува секогаш да ја повторите оваа постапка за потврда на доволно голем број примероци од записите.
- Процена на интегритетот на податоците
Од моментот кога првпат се внесени во компјутер до времето на пристапување до нив, податоците минуваат низ неколку процеси на внесување, чување, пренесување и регистрација. Во секоја од тие фази, тие можеби биле манипулирани од страна на луѓе или од информатички системи.
Заради тоа, често се случува односите помеѓу табелите или полињата да се изгубат или да се измешаат, или некои варијабили да не бидат ажурирани. Токму поради тоа од клучно значење е да се вршат редовни тестови на интегритетот.
На пример, не е необично во базата на податоци на Светската банка да се пронајдат проекти листани како „активни“ и многу години по датумот на нивното одобрување, дури и ако најверојатно голем број од нив одамна не се активни.
За да проверам, подготвив пивот-табела и ги групирав проектите според годината на одобрување. Потоа ги филтрирав податоците за да ми се покажат само проектите означени како „активни“ во колоната „статус на проектот“. Гледаме дека 17 проекти одобрени во 1986, 1987 и 1989 година во базата на податоци сè уште се водат како активни. Речиси сите проекти се спроведуваат во Африка.
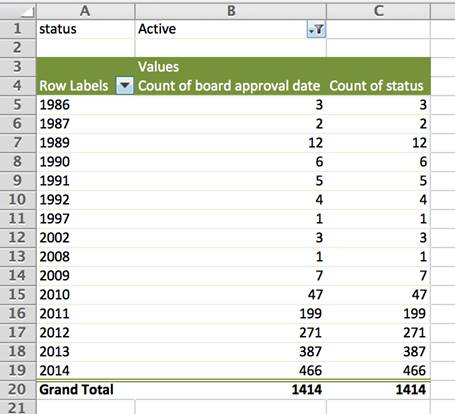
Во овој случај, потребно е да се разјасни, директно со Светската банка, дали тие проекти сè уште се активни по поминати речиси 30 години.
Се разбира, можеме да извршиме и други тестови за да ја процениме конзистентноста на податоците на Светската банка. На пример, добра идеја е да се испита дали сите добитници на заеми (во базата на податоци идентификувани како „borrowers“) се совпаѓаат со организации и/или влади во земјите наведени во полето „Countryname“, или дали државите се класифицирани во соодветниот регион („regionname“).
- Дешифрирање кодови и акроними
Еден добар начин за да ги држите новинарите настрана е да им покажете комплексни информации што содржат специјални шифри и терминологија. Се работи за омилениот трик на бирократите и организациите со ниско ниво на транспарентност. Тие очекуваат дека нема да знаеме како да го разбереме тоа што ни го дале. Но, шифрите и акронимите можат да се искористат и за да се намали бројот на карактери и да се зголемат капацитетите за чување. Речиси сите системи за подготовка на бази на податоци, без оглед на тоа дали се јавни или приватни, користат шифри и акроними за класифицирање на информациите.
Всушност, на многу луѓе, субјекти и предмети на светот им се доделени една или повеќе шифри. Луѓето имаат матични броеви, броеви на социјално осигурување, броеви на сметки во банка, даночни броеви, броеви на корисници на услуги на чести патници, студентски броеви, број на вработен, и сл.
На пример, металните столчиња во светот на меѓународната трговија се заведени под бројот 940179. Секој број на светот има свој единствен ИМО број (International Maritime Organization – IMO). Многу предмети и нешта имаат свој единствен, уникатен број: недвижнини, авиони, компании, компјутери, паметни телефони, пушки, тенкови, таблети, разводи, бракови... Затоа, задолжително треба да се научи како да се дешифрираат шифрите и да се разбере како се користат за да се разбере логиката на базите на податоци и, што е многу позначајно, нивните меѓусебни односи.
Секој од 17-те милиони контејнери за превоз на стока на светот поседува свој единствен идентификациски знак, и ние можеме да го следиме нивното движење ако знаеме дека првите четири букви од идентификацискиот знак се поврзани со идентитетот на сопственикот на контејнерот. Сопственикот можете да го побарате во оваа база на податоци. На тој начин, четирите букви од една таинствена шифра стануваат средство за добивање повеќе информации.
Базата на податоци на проценети проекти на Светската банка е полна со шифри и акроними, а, изненадува тоа што институцијата не објавува унифициран толковник на поими со опис на значењето на сите тие шифри. Некои кратенки и акроними дури и се застарени и се спомнуваат само во стари документи.
На пример, колоната „Lending Instrument“ ги класифицира сите проекти во зависност од 16 видови кредитни инструменти што ги користи Светската банка за финансирање проекти: APL, DPL, DRL, ERL, FIL, LIL, NA, PRC, PSL, RIL, SAD, SAL, SIL, SIM, SSL и TAL. За да ги разбереме податоците, потребно е да го истражиме значењето на тие кратенки. Инаку, нема да знаеме дека ERL се однесува на итните кризни заеми што им се даваат на државите што штотуку минале низ воени судири или природни катастрофи.
Шифрите SAD, SAL, SSL и PSL се однесуваат на оспоруваната Програма за структурни приспособувања (Structural Adjustment Program) што Светската банка ја спроведуваше во 1980-те и 1990-те години. Таа обезбедуваше заеми за државите во економска криза што, за возврат, требаше да ги променат нивните економски политики за да ги намалат своите фискални дефицити. (Програмата беше оспорувана поради влијанието врз социјалната состојба во неколку држави.)
Според Светската банка, од втората половина на 1990-те години, таа е многу повеќе фокусирана на заеми за „развој“, наместо на заеми за приспособување. Од друга страна, според базата на податоци, помеѓу 2001 и 2006 година, повеќе од 150 заеми се одобрени според режимот на Структурни приспособувања.
Дали се работи за грешка во базата на податоци или Програмата за структурни приспособувања е продолжена и во ова столетие?
Овој пример покажува дека декодирањето кратенки не е само добра практика за проценување на квалитетот на податоците, туку, што е уште позначајно, за откривање приказни од јавен интерес.
B. Верификување на податоците по спроведената анализа
Завршниот чекор во верификацијата е фокусиран на вашите наоди и вашата анализа. Се работи, веројатно, за најзначајниот дел од верификацијата, и за лакмусов тест, за да утврдите дали вашата приказна или појдовната хипотеза „држат вода“.
Во 2012 година, работев како уредничка во мултидисциплинарниот тим на весникот „Ла Насион“ во Костарика. Решивме да ја истражиме една од најзначајните програми за јавни субвенции што ги доделуваше владата, позната под името „Avancemos“. Програмата за субвенции им исплаќаше месечни стипендии на сиромашните ученици во јавните училишта за да ги спречи да го напуштат школувањето.
Откако ја обезбедивме базата на податоци со сите стипендирани ученици, ги додадовме и имињата на нивните родители. Потоа ги пребаравме другите бази на податоци за сопственоста на недвижен имот, моторни возила, личен доход и компаниите што работат во земјата. Тоа ни овозможи да создадеме исцрпен список на средствата со кои располагаат индивидуалните семејства. (Тие податоци се јавни во Костарика, со одлука на Врховниот изборен суд.)
Ние тргнавме од хипотезата дека некои од 167.000 стипендирани ученици не живеат во услови на сиромаштија и дека не би требало да ја добиваат месечната стипендија.
Пред анализата, ги проценивме и ги исчистивме сите записи, но и ги верификувавме односите помеѓу индивидуалните лица и нивниот имот.
Анализата откри, меѓу другото, дека татковците на околу 75 ученици месечно заработуваа повеќе од 2.000 американски долари (минималната плата за неквалификуван работник во Костарика изнесува 500 долари) и дека повеќе од 10.000 од нив поседуваат скапи недвижнини или автомобили.
Сепак, дури кога ги посетивме нивните домови можевме да докажеме нешто што податоците сами за себе никогаш немаше да го покажат: тие деца живееја во вистинска сиромаштија со своите мајки, затоа што биле напуштени од нивните татковци.
Никој никогаш не ги прашал за нивните татковци пред да им ја доделат бенефицијата. Како резултат на тоа, државата го финансираше, со јавни пари и во текот на многу години, образованието на голем број деца напуштени од цела армија неодговорни татковци.
Оваа приказна ја сумира најдобрата лекција што ја имам научено во долгите години работа на истражување податоци: Ни најдобрата анализа на податоци не е замена за теренското новинарство и за верификацијата.
